Материализованные представления#
CedrusData позволяет автоматически переписывать пользовательские запросы на материализованные представления в Iceberg. Для ряда сценариев данный функционал позволяет повысить производительность запросов в 5-10 раз и больше, одновременно снижая суммарную нагрузку на кластер.
Вы можете создать одно или несколько материализованных представлений для часто повторяющихся вычислений. После этого CedrusData сможет автоматически подставлять данные материализованные представления в пользовательские запросы.
Сценарии использования#
Автоматическое переписывание запросов на материализованные представления может быть использовано для следующих сценариев:
Уменьшение количества повторяющихся вычислений. В этом случае вы создаете материализованное представление с различными предикатами, агрегатами и операторами Join. Последующе запросы, содержащие идентичные или схожие вычисления, будут сканировать материализованное представление вместо повторного выполнения данных операций. Прикладной пример: ускорение автоматически сгенерированных запросов из BI
Перенос нагрузки из медленных или нагруженных источников в Iceberg. В этом случае вы создаете материализованное представление на основе данных из источника (например, таблицы Greenplum). Последующие запросы к источнику могут быть автоматически переадресованы в Iceberg.
Архитектура#
CedrusData осуществляет следующие шаги для автоматического переписывания запросов на материализованные представления:
Во время обновления материализованного представления с помощью команды
REFRESH MATERIALIZED VIEWCedrusData сохраняет в каталоге Iceberg план запроса, список участвующих в запросе таблиц, а также скалярную оценку предполагаемой выгоды от подстановки данного материализованного представления в запросПри выполнении последующего запроса CedrusData определяет список участвующих в запросе таблиц. После этого CedrusData получает из Iceberg каталога список материализованных представлений, которые потенциально могут быть использованы для переписывания текущего запроса. CedrusData ранжирует полученные материализованные представления в порядке убывания потенциальной выгоды от их подстановки
CedrusData последовательно подставляет материализованные представления в запрос. Для этого CedrusData обходит план запроса снизу вверх, и пытается найти подходящие подпланы, совпадающие или похожие на план материализованного представления. Если CedrusData находит идентичный подплан, происходит его замена материализованным представлением. Если результат подплана может быть получен из материализованного представления путем выполнения дополнительных операций, CedrusData заменяет подплан на материализованное представление и один или несколько компенсирующих операторов.
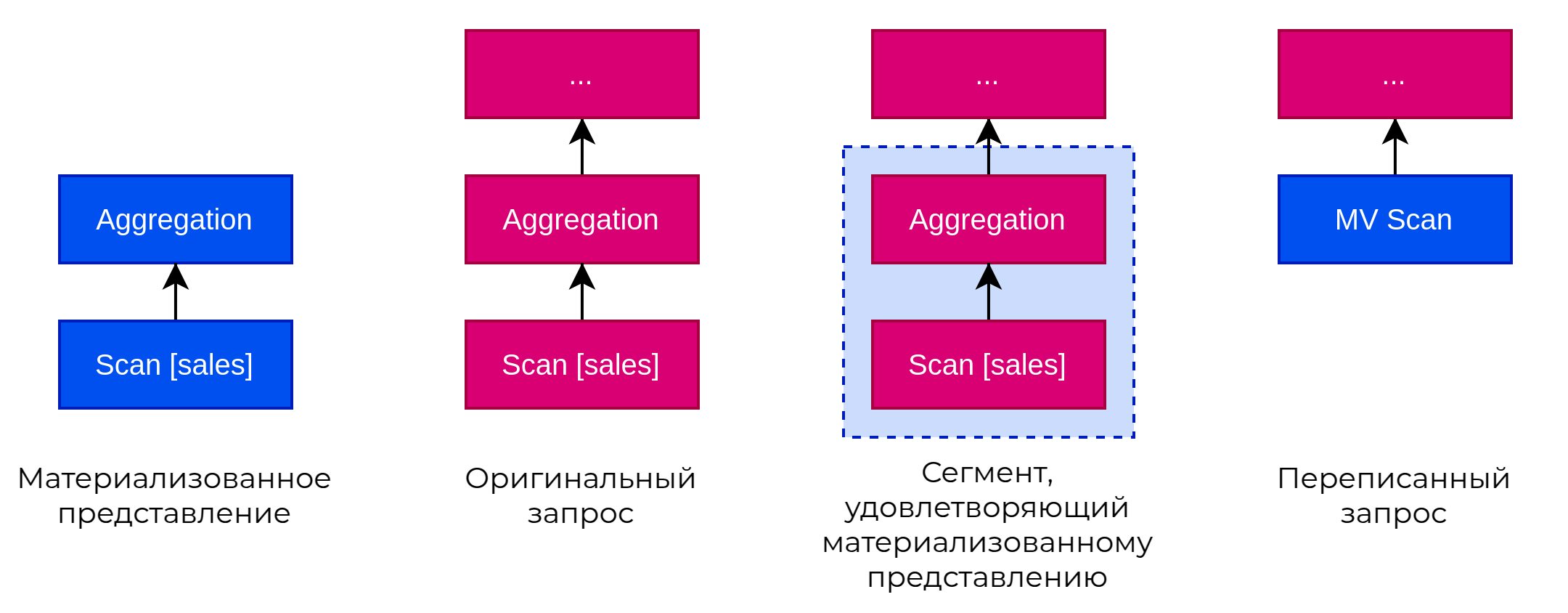
Материализованное представление может быть использовано для переписывания запросов, если выполняется одно из двух условий:
Данные таблиц, на основе которых было построено материализованное представление, не изменились. Доступно только для таблиц Iceberg, в которых проверка актуальности данных происходит путем сравнения snapshot ID
Для материализованного представления задан
GRACE PERIOD, и время последнего обновления произошло не ранее, чем текущее время минус величинаGRACE PERIOD. Данный механизм может быть использован для таблиц из любых источников
Примеры#
Для выполнения описанных ниже примеров вам потребуется запустить CedrusData из Docker-образа и выполнить несколько подготовительных шагов:
Создайте директорию для файлов Iceberg:
mkdir -p data/iceberg
Создайте файл с конфигурацией каталога Iceberg:
echo "connector.name=iceberg iceberg.security=allow-all iceberg.catalog.type=cedrusdata_catalog iceberg.cedrusdata-catalog.catalog-name=local cedrusdata.fs.native-local.enabled=true cedrusdata.local.root-path=iceberg" >> iceberg.properties
Запустите контейнер CedrusData:
docker run -d --rm --name example-cedrusdata-mv \ -e CEDRUSDATA_CATALOG_COORDINATOR_MODE=embedded \ -p 8080:8080 \ -v ${PWD}/data:/data/trino \ -v ${PWD}/iceberg.properties:/etc/trino/catalog/iceberg.properties \ cr.yandex/crpjtvqf29mpabhmrf1s/cedrusdata:458-4
Дождитесь сообщения
======== SERVER STARTED ========в логе контейнера:docker logs example-cedrusdata-mv
Откройте web-интерфейс CedrusData по адресу http://localhost:8080/cedrus-ui, введите произвольное имя пользователя. Выполните следующие команды для создания нескольких таблиц Iceberg с тестовыми данными TPC-H:
CREATE SCHEMA iceberg.tpch; CREATE TABLE iceberg.tpch.nation AS SELECT * FROM tpch.tiny.nation; CREATE TABLE iceberg.tpch.supplier AS SELECT * FROM tpch.tiny.supplier; CREATE TABLE iceberg.tpch.part AS SELECT * FROM tpch.tiny.part; CREATE TABLE iceberg.tpch.partsupp AS SELECT * FROM tpch.tiny.partsupp; USE iceberg.tpch;
Пример 1: Материализация агрегатов#
Данный пример показывает, как материализовать агрегацию по нескольким колонкам и в дальнейшем использовать ее для ускорения запросов по различным измерениям.
Создайте и наполните данными следующее материализованное представление. Мы используем ключевое слово
ROLLUP, которое создает агрегаты по следующим группам колонок:(supplier_name, part_name),(supplier_name),(). Мы также добавляем колонку с функциейgrouping, которая в дальнейшем позволит CedrusData находить внутри материализованного представления агрегаты по разным группам колонок.CREATE MATERIALIZED VIEW mv1 AS SELECT s.name supplier_name, p.name part_name, grouping(s.name, p.name) group_key, sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey GROUP BY ROLLUP (s.name, p.name); REFRESH MATERIALIZED VIEW mv1;
Запустите запрос, который рассчитывает аналогичный агрегат по колонкам
(supplier_name, part_name). Данный запрос не использует материализованное представление, и его выполнение занимает некоторое время. Ознакомьтесь с планом запроса, нажав на кнопку «Отчет о выполнении».SELECT s.name supplier_name, p.name part_name, sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey GROUP BY s.name, p.name;
Включите автоматическое переписывание запросов на материализованные представления:
SET SESSION cedrusdata_materialized_views_rewrite_enabled = true;
Повторно запустите запрос. Теперь он использует материализованное представление, и его выполнение происходит быстрее. Ознакомьтесь с планом запроса, нажав на кнопку «Отчет о выполнении».
SELECT s.name supplier_name, p.name part_name, sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey GROUP BY s.name, p.name;
Запустите ряд схожих запросов, которые рассчитывают тот же агрегат, но по другим ключам группировки:
(supplier_name),(part_name),(). Во всех случаях CedrusData избегает расчета агрегатов с нуля, переиспользуя результат материализованного представления. Обратите особое внимание на запрос, который делает группировку по колонке(part_name). Материализованное представление не содержит данный агрегат. Тем не менее CedrusData успешно задействует материализованное представление путем добавления компенсирующей группировки(part_name)поверх уже рассчитанного агрегата по(supplier_name, part_name).Группировка по
(supplier_name):SELECT s.name supplier_name, sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey GROUP BY s.name;
Группировка по
(part_name):SELECT p.name part_name, sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey GROUP BY p.name;
Без группировки:
SELECT sum(availqty) total_qty FROM partsupp ps INNER JOIN supplier s ON ps.suppkey = s.suppkey INNER JOIN part p ON ps.partkey = ps.partkey;
Пример 2: Материализация подзапросов#
Данный пример показывает, как CedrusData осуществляет множественные подстановки материализованных представлений в запрос.
Создайте материализованное представление, содержащие группировку, фильтр и Join нескольких таблиц:
CREATE MATERIALIZED VIEW mv2 AS SELECT ps.partkey, sum(ps.supplycost * ps.availqty) AS value FROM "partsupp" ps, "supplier" s, "nation" n WHERE ps.suppkey = s.suppkey AND s.nationkey = n.nationkey AND n.name = 'GERMANY' GROUP BY ps.partkey; REFRESH MATERIALIZED VIEW mv2;
Запустите стандартный запрос TPC-H №15. Обратите внимание на его структуру. Сначала запрос рассчитывает агрегат, идентичный материализованному. После этого запрос дополнительно отфильтровывает некоторые строки на основе повторно рассчитанного агрегата с несколько измененным возвращаемым значением. Несмотря на кажущееся отличие в структуре, CedrusData успешно заменяет оба агрегата материализованным представлением, полностью избавляясь от повторных расчетов. Ознакомьтесь с планом запроса, нажав на кнопку «Отчет о выполнении».
SELECT ps.partkey, sum(ps.supplycost * ps.availqty) AS value FROM "partsupp" ps, "supplier" s, "nation" n WHERE ps.suppkey = s.suppkey AND s.nationkey = n.nationkey AND n.name = 'GERMANY' GROUP BY ps.partkey HAVING sum(ps.supplycost * ps.availqty) > ( SELECT sum(ps.supplycost * ps.availqty) * 0.0001 FROM "partsupp" ps, "supplier" s, "nation" n WHERE ps.suppkey = s.suppkey AND s.nationkey = n.nationkey AND n.name = 'GERMANY' ) ORDER BY value DESC;