Развертывание Hive Metastore#
Данное руководство представляет инструкции по развертыванию Hive Metastore на локальном компьютере для тестирования работы CedrusData Engine с озерами данных. Мы будем использовать локальную файловую систему для хранения данных и СУБД Postgres в Docker-контейнере для хранения метаданных.
Процесс развертывания занимает порядка 10-15 минут.
Введение#
Что такое Hive Metastore#
Озеро данных это совокупность файлов, хранящихся в файловой системе (например, HDFS или локальная файловая система) или облаке (например, S3). Для извлечения информации из файлов с помощью SQL необходимы метаданные, которые описывают, как представить информацию из файлов в виде реляционных таблиц. Примерами метаданных являются информация о путях к файлам, информация о колонках и типах данных, информация о partitioning. Hive Metastore представляет собой сервис управления метаданными.
Исторически Hive Metastore был частью инсталляции Hive, распределенного SQL-движка, который позволяет выполнять SQL-запросы к большим данным с помощью map-reduce задач Hadoop. Со временем популярность Hadoop и Hive снизилась, уступив место таким продуктам, как Spark и Trino. Так как Hive Metastore по-прежнему достаточно хорошо справляется с задачами управления метаданным, его продолжают использовать в инсталляциях Spark, Trino и ряда других продуктов в качестве изолированного компонента. Hive Metastore не требует развертывания Hadoop или Hive, но зависит от некоторых библиотек Hadoop.
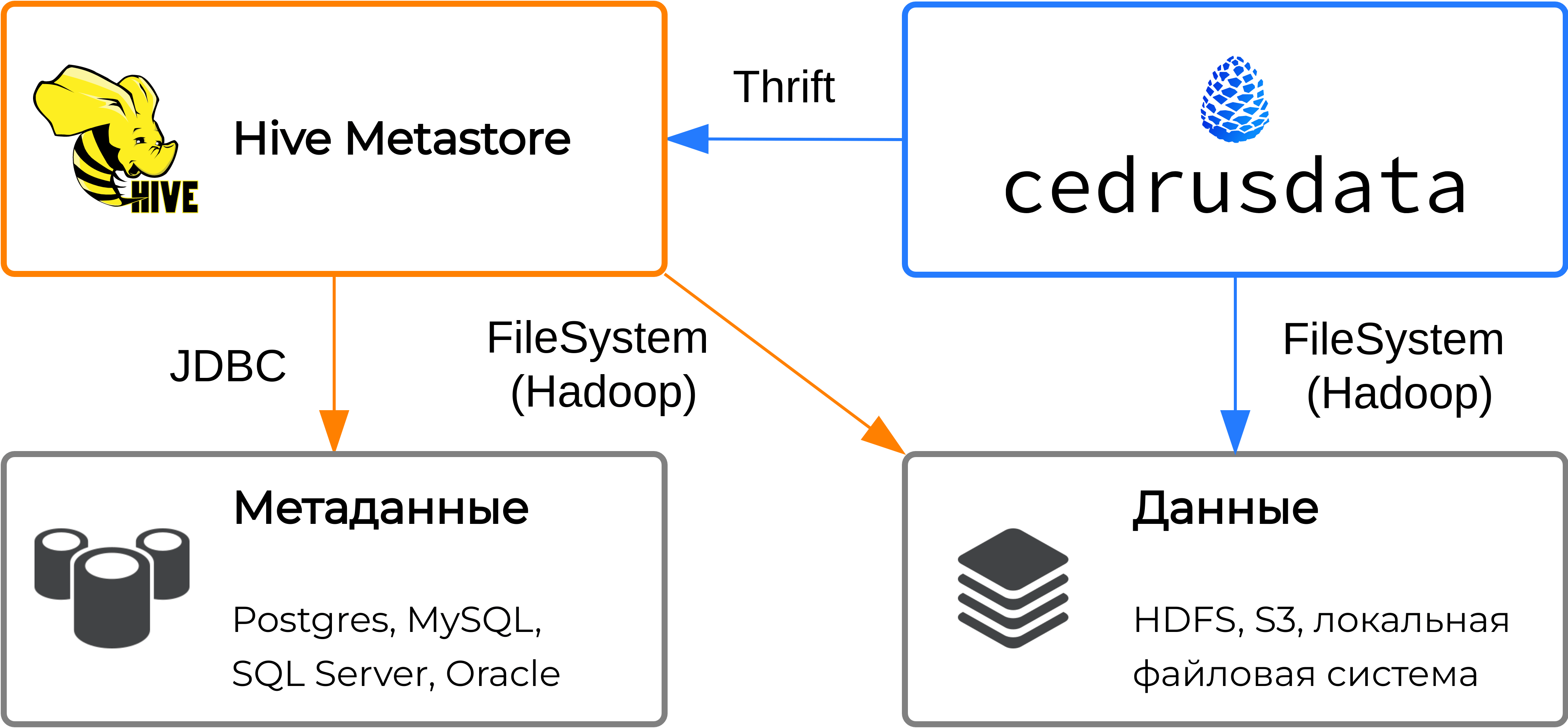
Архитектура Hive Metastore#
Hive Metastore получает запросы на чтение или изменение метаданных от сторонних приложений через встроенный сервер, который работает по протоколу Thrift.
Hive Metastore хранит метаданные в сторонней базе данных для обеспечения сохранности информации в случае перезапуска сервиса. При получении запроса, Hive Metastore получает или обновляет необходимые метаданные в базе данных через интерфейс JDBC.
Некоторые запросы к Hive Metastore требуют изменение данных непосредственно в файловой системе. Например, при получении запроса на создание схемы, необходимо директорию схемы в файловой системе, а при получении запроса на удаление таблицы, необходимо удалить соответствующие файлы.
Для выполнения операций над файловой системой, Hive использует интерфейс Hadoop FileSystem. Файловая система может требовать специфичную конфигурацию. Так, для работы с данными в локальной файловой системе необходимо знать директорию, в которой хранятся данные, а для работы с данными в S3 необходимо предоставить URL и ключи доступа к object storage.
Развертывание Hive Metastore#
Инструкции ниже приведены для операционных систем Ubuntu/Debian с использованием сетевых портов по умолчанию. Адаптируйте инструкции, если вы используете другую операционную систему, или если у вас возникает конфликт портов.
Убедитесь, что у вас установлена JDK 8 или выше. Мы рекомендуем использовать Eclipse Temurin JDK 21, которую можно установить с помощью следующих команд:
wget -O - https://packages.adoptium.net/artifactory/api/gpg/key/public | sudo apt-key add - && \ echo "deb https://packages.adoptium.net/artifactory/deb $(awk -F= '/^VERSION_CODENAME/{print$2}' /etc/os-release) main" | sudo tee /etc/apt/sources.list.d/adoptium.list && \ sudo apt update && \ sudo apt install temurin-21-jdk
Убедитесь, что у вас установлен Docker Engine, и что команда
dockerне требуетsudo.Запустите экземпляр Postgres в Docker-контейнере:
docker pull postgres && \ docker run --name postgres-hive -e POSTGRES_USER=hive -e POSTGRES_PASSWORD=hive -p 5432:5432 -d postgres
Создайте директорию в локальной файловой системе, в которой будут храниться данные. Владельцем директории должен быть пользователь, от имени которого будет запущен Hive Metastore. В данном примере мы создаем директорию
/home/hiveи меняем владельца на текущего пользователя:sudo mkdir /home/hive && \ sudo chown $USER /home/hive
Скачайте и распакуйте дистрибутив Hadoop:
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz && \ tar -xf hadoop-3.3.4.tar.gz
Скачайте и распакуйте дистрибутив Hive Metastore:
wget https://archive.apache.org/dist/hive/hive-standalone-metastore-3.0.0/hive-standalone-metastore-3.0.0-bin.tar.gz && \ tar -xf hive-standalone-metastore-3.0.0-bin.tar.gz
Скачайте JDBC драйвер Postgres, и переместите его в поддиректорию
lib/в директории дистрибутива Hive Metastore:export HIVE_HOME=<директория дистрибутива Hive Metastore> && \ wget https://jdbc.postgresql.org/download/postgresql-42.5.0.jar -P $HIVE_HOME/lib
В директории дистрибутива Hive Metastore задайте следующее содержимое файлу
conf/metastore-site.xml. Важными значениями являются (1) порт сервера Thrift в параметрахhive.metastore.portиmetastore.thrift.uris, (2) порт Postgres в параметреjavax.jdo.option.ConnectionURLи (3) директория, в которой будут храниться файлы в параметреmetastore.warehouse.dir. Измените соответствующие параметры, если вы используете другие порты или другую директорию.<configuration> <property> <name>hive.metastore.port</name> <value>9083</value> </property> <property> <name>metastore.thrift.uris</name> <value>thrift://localhost:9083</value> </property> <property> <name>metastore.task.threads.always</name> <value>org.apache.hadoop.hive.metastore.events.EventCleanerTask</value> </property> <property> <name>metastore.expression.proxy</name> <value>org.apache.hadoop.hive.metastore.DefaultPartitionExpressionProxy</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.postgresql.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:postgresql://localhost:5432/hive</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>metastore.warehouse.dir</name> <value>/home/hive</value> </property> </configuration>
Задайте переменные окружения
JAVA_HOMEиHADOOP_HOME:export JAVA_HOME=<директория установки JDK> && \ export HADOOP_HOME=<директория дистрибутива Hadoop>
Во многих случаях директорию установки JDK можно узнать с помощью следующей команды:
echo $(dirname $(dirname $(readlink -f $(which java))))
Из директории дистрибутива Hive Metastore инициализируйте схему Hive Metastore в Postgres:
bin/schematool -initSchema -dbType postgres
Из директории дистрибутива Hive Metastore запустите Hive Metastore:
bin/start-metastore
На этом процесс развертывания Hive Metastore завершен.
Проверка работы Hive Metastore с CedrusData Engine#
Для проверки работы Hive Metastore с CedrusData Engine, мы запустим узел CedrusData Engine с каталогом Hive коннектора, после чего выполним ряд SQL-запросов.
Установите CedrusData Engine из архива согласно инструкции Установка из архива.
Сконфигурируйте каталог для работы с Hive Metastore. Для этого в директории CedrusData Engine создайте файл
etc/catalog/hive.propertiesсо следующим содержимым:connector.name=hive hive.metastore.uri=thrift://localhost:9083 hive.security=allow-all hive.max-partitions-per-writers=1000000
Из директории дистрибутива CedrusData Engine перезапустите узел:
bin/launcher restartИз директории дистрибутива CedrusData Engine выполните следующие команды для создания схемы в Hive Metastore, и создания и наполнения таблицы
call_centerв форматеParquet <https://parquet.apache.org/>_:bin/trino --execute "create schema hive.my_tpcds" && \ bin/trino --execute "create table hive.my_tpcds.call_center with (format = 'PARQUET') as select * from tpcds.sf1.call_center"
Из директории дистрибутива CedrusData Engine выполните следующую команду для чтения данных из таблицы
call_center:bin/trino --execute "select cc_call_center_id, cc_name from hive.my_tpcds.call_center"
Убедитесь, что в директории Hive Metastore
/home/hiveпоявился файл таблицыcall_center:ls -R /home/hive
Из директории дистрибутива CedrusData Engine выполните следующие команды для удаления таблицы и схемы в Hive Metastore:
bin/trino --execute "drop table hive.my_tpcds.call_center" && \ bin/trino --execute "drop schema hive.my_tpcds"
Убедитесь, что директория Hive Metastore
/home/hiveбольше не содержит вложенных файлов и директорий:ls -R /home/hive